
Roby Yasir Amri
:date_full
How to Configure High Availabilty Kubernetes Cluster on Ubuntu 20.4
On this occasion I will share how to configure High Availability Cluster Kubernetes on Ubuntu using HAProxy and Keepalive. We use Keepalive and HAproxy for load balancing and high availability. Things that need to be prepared include:
- Hosts/Instances/VM
- Configure HAproxy and Keepalive
- Configure Kubernetes clustering using Kubeadm.
Architecture Clusters.
Here we use 3 masters, 3 workers, 2 load balancers, and 1 IP to be used as a Virtual IP Address. VIP means that if an error occurs or 1 node dies, the IP can be forwarded to the node that allows flaiover to occur, so that High Availability is achieved according to our current lab goals.
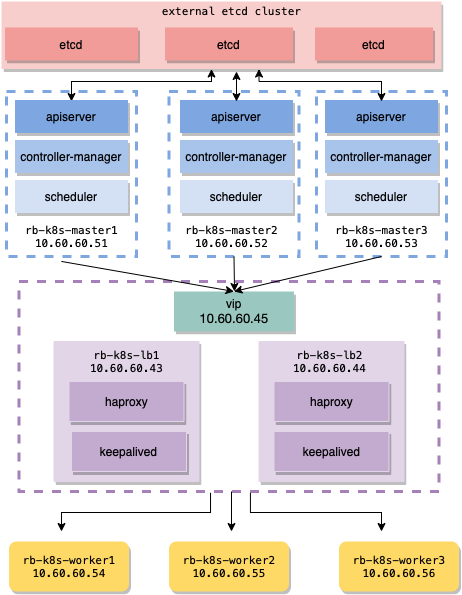
It should be underlined, that HAproxy and Keepalive are not installed on the master node. HAproxy and Keepalive are only installed on loadbalancer1 and loadbalancer2 nodes
Hosts used:
| Hostname | IP Address | Roles |
|---|---|---|
| rb-k8s-lb1 | 10.60.60.43 | HAproxy & Keepalived |
| rb-k8s-lb2 | 10.60.60.44 | HAproxy & Keepalived |
| rb-k8s-master1 | 10.60.60.51 | master, etcd |
| rb-k8s-master2 | 10.60.60.52 | master, etcd |
| rb-k8s-master3 | 10.60.60.53 | master, etcd |
| rb-k8s-worker1 | 10.60.60.54 | worker |
| rb-k8s-worker2 | 10.60.60.55 | worker |
| rb-k8s-worker3 | 10.60.60.56 | worker |
| - | 10.60.60.45 | VirtualIP |
Load Balancing Configuration:
Keepalived and HAproxy are installed on nodes rb-k8s-lb1 and rb-k8s-lb2. In this scenario, if one of the loadbalancer nodes is down/dead, Virtual IP will automatically use the path on the loadbalancer node that is running so that the Kubernetes cluster does not experience an error.
Install Keepalive and HAproxy on both nodes
- Run on nodes rb-k8s-lb1 and rb-k8s-lb2:
sudo apt install keepalived haproxy psmisc -y
- Configure haproxy on both loadbalancer nodes:
sudo vi /etc/haproxy/haproxy.cfg
global
log /dev/log local0 warning
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
log global
option httplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
frontend kube-apiserver
bind *:6443
mode tcp
option tcplog
default_backend kube-apiserver
backend kube-apiserver
mode tcp
option tcplog
option tcp-check
balance roundrobin
default-server inter 10s downinter 5s rise 2 fall 2 slowstart 60s maxconn 250 maxqueue 256 weight 100
server rb-k8s-master1 10.60.60.51:6443 check # Replace the IP address with your own.
server rb-k8s-master2 10.60.60.52:6443 check # Replace the IP address with your own.
server rb-k8s-master3 10.60.60.53:6443 check # Replace the IP address with your own.
- Restart service HAproxy:
sudo systemctl restart haproxy
- Then restart and enable the HAproxy service:
sudo systemctl enable haproxy
sudo systemctl restart haproxy
- Make sure the HAproxy service is active:
root@rb-k8s-lb1:~# systemctl status haproxy.service
● haproxy.service - HAProxy Load Balancer
Loaded: loaded (/lib/systemd/system/haproxy.service; enabled; vendor preset: enabled)
Active: active (running) since Sat 2022-02-12 17:29:05 UTC; 10min ago
Docs: man:haproxy(1)
file:/usr/share/doc/haproxy/configuration.txt.gz
Process: 463986 ExecStartPre=/usr/sbin/haproxy -f $CONFIG -c -q $EXTRAOPTS (code=exited, status=0/SUCCESS)
Main PID: 464001 (haproxy)
Tasks: 5 (limit: 4676)
Memory: 3.6M
CGroup: /system.slice/haproxy.service
├─464001 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
└─464002 /usr/sbin/haproxy -Ws -f /etc/haproxy/haproxy.cfg -p /run/haproxy.pid -S /run/haproxy-master.sock
Feb 12 17:29:05 rb-k8s-lb1 systemd[1]: Starting HAProxy Load Balancer...
Feb 12 17:29:05 rb-k8s-lb1 haproxy[464001]: [WARNING] 042/172905 (464001) : parsing [/etc/haproxy/haproxy.cfg:28] : backend 'kube-apiserver' >
Feb 12 17:29:05 rb-k8s-lb1 haproxy[464001]: [NOTICE] 042/172905 (464001) : New worker #1 (464002) forked
Feb 12 17:29:05 rb-k8s-lb1 systemd[1]: Started HAProxy Load Balancer.
Feb 12 17:29:08 rb-k8s-lb1 haproxy[464002]: [WARNING] 042/172908 (464002) : Server kube-apiserver/rb-k8s-master2 is DOWN, reason: Layer4 conn>
Feb 12 17:29:12 rb-k8s-lb1 haproxy[464002]: [WARNING] 042/172912 (464002) : Server kube-apiserver/rb-k8s-master3 is DOWN, reason: Layer4 conn>
Keepalive Configuration
- Configure keepalive on both nodes rb-k8s-lb1 and rb-k8s-lb2:
sudo /etc/keepalived/keepalived.conf
Configure keepalive.conf on rb-k8s-lb1:
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 100
interface ens3 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 10.60.60.43 # The IP address of this machine rb-k8s-lb1
unicast_peer {
10.60.60.44 # The IP address of peer machines rb-k8s-lb2
}
virtual_ipaddress {
10.60.60.45/24 # The VIP address
}
track_script {
chk_haproxy
}
}
Configure keepalive.conf on rb-k8s-lb2:
global_defs {
notification_email {
}
router_id LVS_DEVEL
vrrp_skip_check_adv_addr
vrrp_garp_interval 0
vrrp_gna_interval 0
}
vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance haproxy-vip {
state BACKUP
priority 100
interface ens3 # Network card
virtual_router_id 60
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
unicast_src_ip 10.60.60.44 # The IP address of this machine rb-k8s-lb2
unicast_peer {
10.60.60.43 # The IP address of peer machines rb-k8s-lb1
}
virtual_ipaddress {
10.60.60.45/24 # The VIP address
}
track_script {
chk_haproxy
}
}
- Then restart and enable the keepalive service
sudo systemctl enable keepalived
sudo systemctl restart keepalived
- Make sure the service keepalived is running Status keepalived on rb-k8s-lb1:
root@rb-k8s-lb1:~# sudo systemctl status keepalived.service
● keepalived.service - Keepalive Daemon (LVS and VRRP)
Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-02-02 16:07:10 UTC; 1 weeks 3 days ago
Main PID: 647 (keepalived)
Tasks: 2 (limit: 4676)
Memory: 6.5M
CGroup: /system.slice/keepalived.service
├─647 /usr/sbin/keepalived --dont-fork
└─708 /usr/sbin/keepalived --dont-fork
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: Registering Kernel netlink command channel
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: Opening file '/etc/keepalived/keepalived.conf'.
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: WARNING - default user 'keepalived_script' for script execution does not exist - please crea>
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: WARNING - script `killall` resolved by path search to `/usr/bin/killall`. Please specify ful>
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: SECURITY VIOLATION - scripts are being executed but script_security not enabled.
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: Registering gratuitous ARP shared channel
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: (haproxy-vip) Entering BACKUP STATE (init)
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: VRRP_Script(chk_haproxy) succeeded
Feb 02 16:07:10 rb-k8s-lb1 Keepalived_vrrp[708]: (haproxy-vip) Changing effective priority from 100 to 102
Feb 02 16:07:14 rb-k8s-lb1 Keepalived_vrrp[708]: (haproxy-vip) Entering MASTER STATE
Status keepalived on rb-k8s-lb2:
root@rb-k8s-lb2:~# sudo systemctl status keepalived.service
● keepalived.service - Keepalive Daemon (LVS and VRRP)
Loaded: loaded (/lib/systemd/system/keepalived.service; enabled; vendor preset: enabled)
Active: active (running) since Wed 2022-02-02 16:07:12 UTC; 1 weeks 3 days ago
Main PID: 647 (keepalived)
Tasks: 2 (limit: 4676)
Memory: 6.6M
CGroup: /system.slice/keepalived.service
├─647 /usr/sbin/keepalived --dont-fork
└─699 /usr/sbin/keepalived --dont-fork
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: Registering Kernel netlink reflector
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: Registering Kernel netlink command channel
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: Opening file '/etc/keepalived/keepalived.conf'.
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: WARNING - default user 'keepalived_script' for script execution does not exist - please crea>
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: WARNING - script `killall` resolved by path search to `/usr/bin/killall`. Please specify ful>
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: SECURITY VIOLATION - scripts are being executed but script_security not enabled.
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: Registering gratuitous ARP shared channel
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: (haproxy-vip) Entering BACKUP STATE (init)
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: VRRP_Script(chk_haproxy) succeeded
Feb 02 16:07:13 rb-k8s-lb2 Keepalived_vrrp[699]: (haproxy-vip) Changing effective priority from 100 to 102
High Availability Verification
Before we create a kubernetes cluster we have to make sure our high availability configuration is working properly.
- Check the IP Address on the node rb-k8s-lb1:
root@rb-k8s-lb1:~# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:72:9a:4b brd ff:ff:ff:ff:ff:ff
inet 10.60.60.43/24 brd 10.60.60.255 scope global ens3
valid_lft forever preferred_lft forever
inet 10.60.60.45/24 scope global secondary ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe72:9a4b/64 scope link
valid_lft forever preferred_lft forever
We can see that VIP 10.60.60.45 was successfully added to the node rb-k8s-lb1. then we simulate if node rb-k8s-lb1 is down, then VIP 10.60.60.45 should automatically move to node rb-k8s-lb2
- We turn off the HAproxy service on the rb-k8s-lb1 node:
sudo systemctl stop haproxy.service
- Then we check again the IP Address on the node rb-k8s-lb1:
root@rb-k8s-lb1:~# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:72:9a:4b brd ff:ff:ff:ff:ff:ff
inet 10.60.60.43/24 brd 10.60.60.255 scope global ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe72:9a4b/64 scope link
valid_lft forever preferred_lft forever
At node rb-k8s-lb1 VIP 10.60.60.45 no longer exists, then we have to make sure if VIP is at node rb-k8s-lb2
- Check the IP Address on the rb-k8s-lb2 node:
root@rb-k8s-lb2:~# ip a
1: lo: mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens3: mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:aa:3d:02 brd ff:ff:ff:ff:ff:ff
inet 10.60.60.44/24 brd 10.60.60.255 scope global ens3
valid_lft forever preferred_lft forever
inet 10.60.60.45/24 scope global secondary ens3
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:feaa:3d02/64 scope link
valid_lft forever preferred_lft forever
As per our expectation that VIP has moved to node rb-k8s-lb2 if simulated node rb-k8s-lb1 is dead by disabling haproxy service on rb-k8s-lb1.
- Don’t forget to start the haproxy service again on node rb-k82-lb1:
sudo systemctl start haproxy.service
In the next post we will continue with configuring the Kubernetes cluster using the VIP address we created earlier